Scheduling In Go : Part I - OS Scheduler

文章目录
此文是系列文章的第一篇,将提供对操作系统调度的理解。 - 第一篇:Scheduling In Go : Part I - OS Scheduler - 第二篇:Scheduling In Go : Part II - Go Scheduler - 第三篇:Scheduling In Go : Part III - Concurrency
Introduction
Go调度的设计与实现提供了高效率和高性能的多线程,然而如果你的Go程序多线程设计不支持Go调度的工作,那这也将无济于事。本文主要集中于调度程序的高级机制和语义,展现出多线程工作的一些细节,从而帮助你更好的做出工程决策。
OS Scheduler
操作系统调度器是软件非常重要的部分。我们的程序在运行运行的时候只是一串需要被顺序执行的指令,为了执行这些指令,操作系统引入了线程。线程的任务就是管理和执行分配给它的一系列指令,持续执行直到此线程没有等待执行的指令为止,这也就是我把线程称作“执行路径”。 每个运行的程序都会创建一个进程并且每个进程都会被分配一个初始的线程。线程可以创建更多线程。所有不同的线程运行相互独立并且调度决定是在线程级别而不是进程级别做出的。线程运行可以是并发的(每个线程在一个独立核上轮流运行),也可以是并行的(每个线程在不同的核上同时运行)。线程会保持它们自己本身的状态来保证它们的指令安全、局部并且相互独立的执行。 操作系统调度器负责确保如果有线程可以执行的时候内核不空闲。这会让你产生错觉仿佛所以的可执行线程在同时执行。导致这个错觉的过程中,调度器需要运行更高优先级的线程。然而,更低优先级的线程不能一直不被执行。因此,调度器还需要通过通过快速又智能的决策尽可能地减少调度延迟。 很多人对算法的不断改进和完善才实现了它,幸运的是现在我们有好几十年的工作和工程经验可以学习和借鉴。为了更好的理解操作系统调度器,我们需要描述和定义几个重要概念。
Executing Instructions
程序计数器(PC),有时也称作指令指针(IP),线程用来跟踪下一条要执行的指令。在大多数处理器中,PC执行下一条指令而非当前指令。
Figure 1
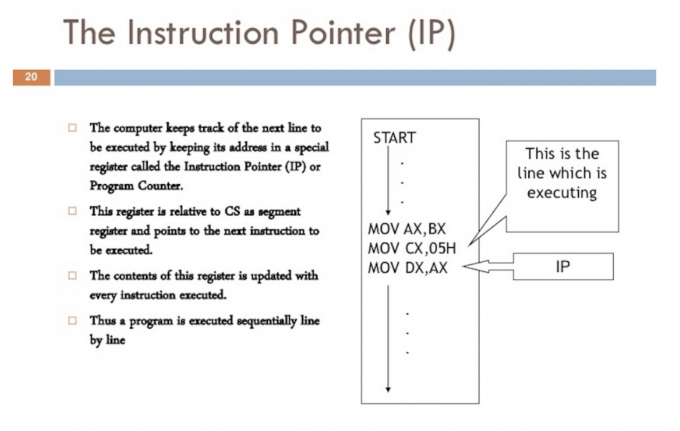
如果你从Go程序中看过栈跟踪,你可能会注意到在每行末尾的那些小的十六进制数字,比如在Listing 1中的 +0x39 和 +0x72。
Listing 1
|
|
那些数字代表了各自顶部函数的PC偏移值。+0x39 PC偏移值代表了example函数如果没有抛出异常的时候线程将执行的下一个指令。+0x72 PC偏移值则表示如果控制恰好回到main函数的话,main函数内部将要执行的下一个指令。更重要的是,指针之前的指令会告诉我们正在执行的指令是什么。
接下来看Listing2 中的程序,这个程序就是导致Listing 1中栈跟踪的程序。
Listing 2
|
|
十六进制数字 +0x39 代表了在函数example中一个指令的PC偏移值是位于函数开始指令下的57(十进制)bytes。在下面Listing 3中,你可以看到函数example在二进制中的objdump。找到第12行,也就是最后一行,可以看到这行上面的一行调用了panic。
Listing 3
|
|
注意:PC是指向下一个指令,而不是当前指令。Listing 3是一个很好的基于amd64的指令示例,该Go程序的线程负责按顺序执行这些指令。
Thread States
另一个重要的概念就是线程状态,它代表了线程在调度器中的角色。线程有三种状态:等待,可执行和执行中。 - 等待:这意味着线程被停止并等待某个东西以继续,可能是等待硬件(磁盘,网络),操作系统(系统调用)或者是同步调用(原子,锁)。这些延迟类型是性能差的根因。 - 可运行:这意味着线程需要等待内核上的时间,以便执行分配给其的机器指令。如果你有大量线程想要内核时间,这意味着线程需要等待更长时间来获得内核时间。而且,随着更多线程争夺时间,任何给定线程获得的时间都会缩短。这种调度延时也是降低性能的一个原因。 - 执行中:这意味着线程已经被放在核心上,并且正在执行其机器指令,与应用程序相关的工作正在完成。
Types Of Work
线程有两种类型工作,一种是计算密集型,另一种是IO密集型。 - 计算密集型(CPU-Bound):这种工作类型永远不会造成线程处于等待状态的情况,这种工作会持续进行计算,例如将Pi计算到第N位。 - IO密集型(IO-Bound):这种工作类型会使线程进入等待状态,这种类型工作有通过网络请求接入资源或者在操作系统进行系统调用。线程需要访问数据库就是一种IO密集型工作。
Context Switching
Linux, Mac or Windows系统是抢占式调度器。这意味几个重要问题。其一,有时钟到来时调度是不可预测的,我们无法预测什么线程会被选中运行。线程优先级与事件一起(例如在网络上接收数据)使得无法确定调度程序将选择执行什么操作以及何时执行。
其二,这意味着你一定不能基于一些感知行为来编写代码,这些感知行为你有幸经历过,但是无法保证每次都会发生。你很容易认为,我已经见过同样的方式发生1000次了,这种行为是可靠的。如果应用程序中需要确定性,则必须控制线程的同步和编排。
在一个内核上交换线程的物理行为被称作上下文切换。上下文切换发生在调度器从内核中提取一个正在执行的线程并用一个可运行的线程替换它。这个被选中的线程从可执行队列转变为执行中状态。而被替换下的线程则被放回可运行队列(如果它仍有能力运行),或者等待队列(如果它是因为等待IO密集型请求而被替换)。
上下文切换被认为是昂贵的,因为在内核上和内核下交换线程需要时间。上下文切换过程中产生的延迟量取决于不同的因素,但在1000到1500纳秒之间进行切换并非不合理。考虑到硬件应该能够合理地(平均)每纳秒每核执行12条指令,一个上下文切换会花费大约12k到18k条指令的延迟。实际上,在上下文切换期间,程序正在失去执行大量指令的能力。
如果你有一个主要是IO密集型的程序,上下文切换会成为一个优势。一旦一个线程被移到等待状态,可运行状态的线程将立马取代它。这使得内核始终处于工作状态。这是调度非常重要的一个方面,只要有工作可以执行(可运行状态线程),内核则不能空闲。
如果你的程序是CPU密集型,上下文切换将成为性能噩梦。尽管内核一直有线程在执行,但是上下文切换会一直停止程序正在执行的工作。这种情况与IO密集型工作负载的情况形成鲜明对比。
Less Is More
早些时候,处理器是单核的,调度并没有那么复杂。因为你只有一个单核处理器,任何给定时间只能执行一个线程。想法就是定义一个调度周期并且在这个调度周期内尝试执行所有的可运行线程。这是没问题的,我们取调度周期除以需要执行的线程数。
举个例子,如果你将调度周期定义为10ms并且你有2个线程,那么每个线程会得到5ms运行时间。如果你有5个线程,则每个线程则得到2ms。然而,如果你有100个线程会怎么样呢?如果每个线程分配时间片10μs (微秒)是不可行的,因为,这样你将花费大量时间在上下文切换上面。 你需要做的是限制时间片的长度。在上面那个问题中,如果最小的时间片长度设置为2ms而你又100个线程,调度周期就应该增加的2000ms也就是2s。那如果是1000个线程呢,现在你也可以容易得出调度周期应为20s。如果每个线程完全使用它的时间片的情况下,在这个简单例子中,每个线程恰好运行一次则将花费20s。
要知道上面的例子是一个非常简单的认识。其实,在作出调度决定时,调度器往往需要考虑和处理很多因素。你自行控制在自己程序中的线程数目。当有更多的线程需要考虑,并且IO密集型的工作发生时,就会有更多的混乱和不确定性行为,就会需要更多地时间去调度和执行。
这就是为什么游戏规则是“少即是多”。处于可运行状态的线程越少,意味着调度开销越少,每个线程得到的时间越长。处于可运行状态的线程越多,意味着每个线程得到的时间越少。这也就意味着随着时间的推移会完成更少工作。
Find The Balance
你需要在是你的程序获得最佳吞吐量的核数与线程数之间找到一个平衡。当谈到管理平衡,线程池是一个非常好的方案。在这个系列文章Part II中我会说明对Go而言这种方案已经不再必要。我认为这是Go语言使多线程应用程序开发更容易的好事之一。
在使用Go编程之前,我用过C++、C#和NT。在那种操作系统中,使用IOCP线程池对编写多线程软件是非常重要的。作为一个工程师,你需要计算出你需要的线程池数目以及对于任何给定的线程池最大化给定核数的吞吐量的最大线程数。
当编写需要同数据库交互的Web服务时,每个核心3个线程的神奇数量似乎总是在NT上提供最好的吞吐量。换句话说,每个核心3个线程会在最小化上下文切换的延时的同时最大化在核上面的执行时间。当创建IOCP线程池时,我知道在主机每个核心上定义线程数范围为[1,3]。
如果我每个核心使用两个线程,将所有工作完成会花费更长时间,这是因为当我在工作过程中会有空闲的时间。 如果我每个核心使用四个线程,将所有工作完成也会花费更长时间,因为我会在上下文切换上有更多的延时。不管出于什么原因,每个核心3个线程的平衡似乎总是NT上的神奇数字。
如果你的服务正在进行很多不同类型的工作会怎么样呢?那将会产生不同且不一致的延时。对于所有不同的工作负载,我们可能无法找到一个一直有效的魔法数字。当讲到使用线程池来协调服务性能时,找到正确的一致配置会变得非常复杂。
Cache Lines 从主存访问数据具有很高的延迟成本(大约100到300个时钟周期),因此处理器和内核具有本地缓存,以使数据接近需要它的硬件线程。从缓存访问数据的成本要低得多(大约3到40个时钟周期),这取决于被访问的缓存。如今,性能的一个方面是如何高效地将数据输入处理器以减少这些数据访问延迟。编写会使状态发生改变的应用程序需要考虑缓存系统机制。
Figure 2
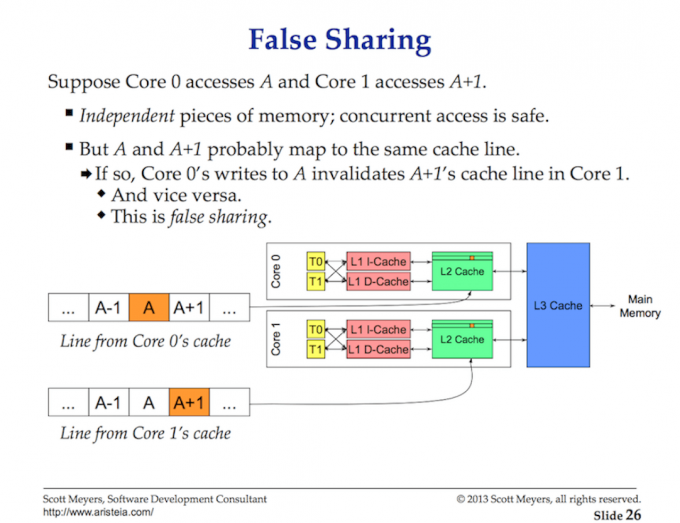
数据通过缓存行( cache lines)在处理器和主存之间交换。一个缓存行是一个64位的内存块,它在主存和缓存系统中被交换。每个核心都有自己所需缓存行的副本,这意味着硬件使用值语义( value semantics)。这就是为什么多线程应用程序中内存的变化会造成性能噩梦的原因。
当多个并行运行的线程正在访问相同的数据值,甚至彼此相邻的数据值时,它们将访问同一缓存行上的数据。在任何核心上运行的任何线程都将获得同一缓存行的自己的副本。
Figure 3

如果给定核心上的一个线程更改了其缓存行副本,那么通过硬件磁性,同一缓存行的所有其他副本都必须标记为脏。当线程尝试对脏缓存行进行读或写访问时,主存访问需要(大约100到300个时钟周期)获取缓存行的新副本。
或许对于两核的处理器而言小菜一碟,但是如果是并行运行着32个线程的32核处理器,并且都在对同一个缓存行进行数据访问和修改会怎么样呢?一个有着两个物理处理器并且每个物理处理器有16核的系统又会怎么样呢?这将变得更糟,因为处理器到处理器通信的延迟增加了。应用程序将在内存中受到重创,性能将非常糟糕,而且很可能,你将无法理解这是为什么。
这被称作缓存一致性问题并且也会引入像是错误共享(false sharing)这种问题。在编写将改变共享状态的多线程应用程序时,必须考虑缓存系统。
Scheduling Decision Scenario
假设我让你根据我给你的高级信息编写操作系统调度程序,想想你必须考虑的一个场景。记住,这是调度器在做出调度决策时必须考虑的许多有趣的事情之一。 你开启了你的程序,主线程被创建并且在核1上运行。随着线程开始执行它的指令,缓存行由于数据需要而正在被恢复。这个线程决定为当前正在运行的进程创建一个新的线程,那么问题来了。 一旦线程被创建并且准备执行,调度器是不是应该:
- 上下文切换主线程离开核1?这样做将有利于提高性能,因为这个新线程需要已经缓存的相同数据的可能性非常大。但是主线程没有获得它完整的时间片。
- 新的线程是不是要等待核1直到主线程时间片完成?线程没有执行,但是一点线程开始执行,获取数据的延时会被消除。
- 新的线程是否要等待新的可用的核?这意味着选定核的缓存行将被刷新、检索和复制,从而导致延迟。但是,线程会更快地启动,主线程可以完成其时间片。
玩得开心吗?当调度器做出调度决定时,它需要考虑很多有趣的事情。幸运的是,不是我做的。我只能告诉你,如果有一个空闲的内核,它将被使用。你希望线程在可以运行时运行。
Conclusion
本文的第一部分提供了在编写多线程应用程序时,你必须考虑的线程和操作系统调度程序的细节。这些也是Go调度器要考虑的因素。在下一篇文章中,我将描述Go调度器的语义,以及它们与此信息的关系。最后,通过运行几个程序,你将看到所有这些都在起作用。